🧭 Foundry MVP Architecture - Comprehensive Overview
1. Executive Summary
Goal:
Develop an MVP platform that replicates the core capabilities of Palantir Foundry — transforming fragmented enterprise data into continuous operational intelligence — using open-source and cloud-native components.
Scope:
The MVP unifies three key capabilities:
- Closed-loop analytics and feedback capture
- A graph-based ontology modeling entities, events, and processes
- AI-driven intelligence loops that evolve from both user and system decisions
Strategic Insight:
Palantir's differentiation lies in its Ontology—a semantic system that represents how an enterprise operates and learns. Combined with Foundry's closed-loop design, it enables a continuously self-improving digital twin of the organization.
The MVP achieves approximately 70–80% functional coverage of Foundry's decision-intelligence capability at less than 10% of its cost and complexity, ideal for startups and mid-size enterprises.
2. Strategic Context & Business Objectives
| Objective | Description | Outcome |
|---|---|---|
| Unified Data Understanding | Integrate disparate data into a single semantic model of real-world entities | Shared visibility and context |
| Operational Intelligence | Map real-time events and actions to entities | Live, contextual operational view |
| Decision Feedback Loop | Capture user and AI decisions to improve data and models | Continuous organizational learning |
| Governance & Trust | Maintain lineage, versioning, and access control | Data integrity and auditability |
| AI-Driven Optimization | Attach and retrain models based on feedback | Adaptive, self-improving processes |
3. Functional Overview
3.1 Foundry's Closed-Loop Operational Paradigm
Traditional analytics architectures are linear, moving from data ingestion to dashboards. Foundry redefines this as a bidirectional system that not only delivers insights but captures decisions and feeds them back into models and processes.
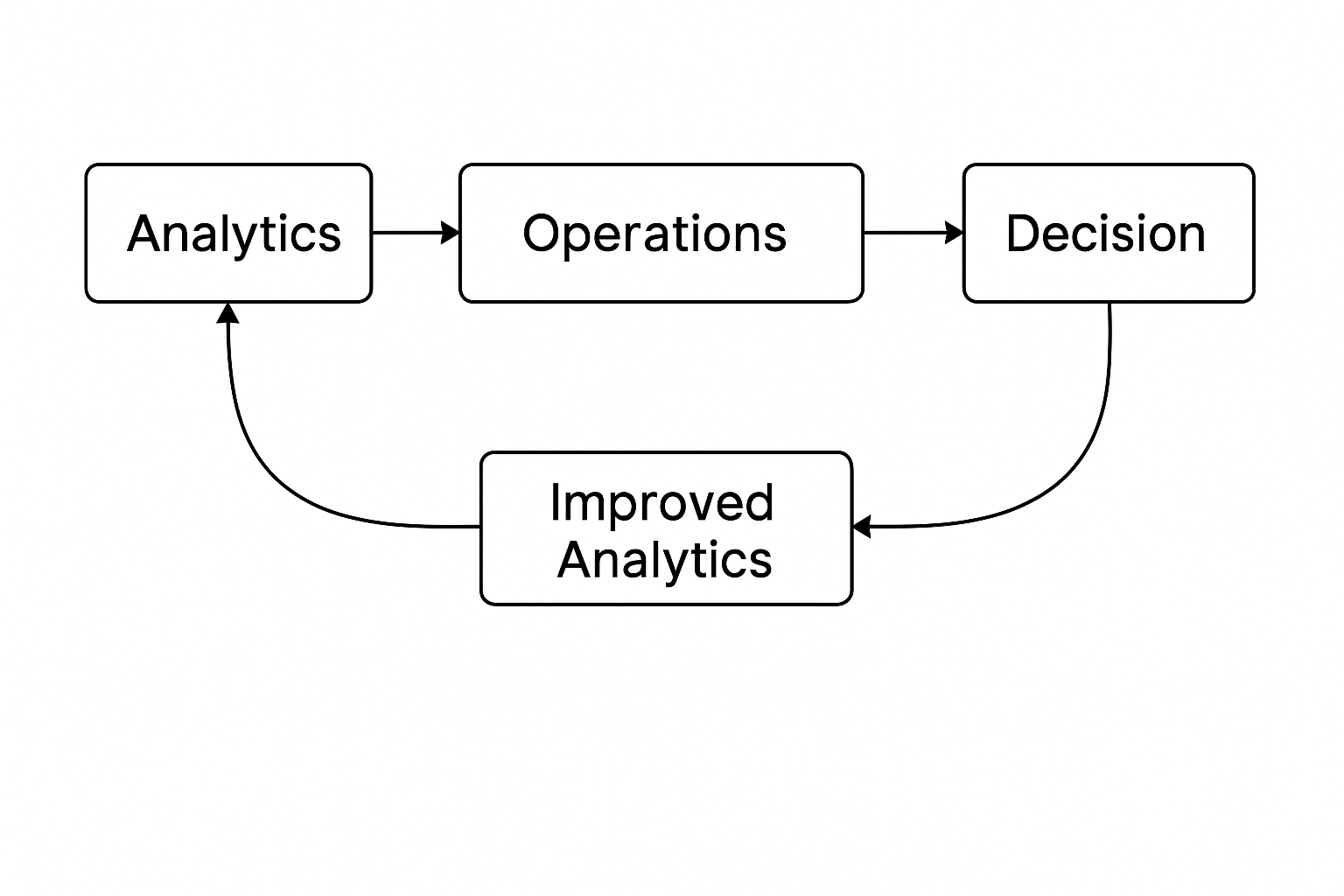
Analytics → Operations → Decision → Feedback → Improved Analytics
This closed loop ensures that every user interaction strengthens the data foundation and operational models.
3.2 The Palantir Ontology
→ View detailed Ontology Layer documentation
| Layer | Function | Analogy |
|---|---|---|
| Semantic (Nouns) | Defines business entities (customers, assets, products) with unified meaning derived from multiple data sources | The organization's language |
| Kinetic (Verbs) | Represents dynamic actions (transactions, maintenance, orders) as graph-linked events | The organization's motion |
| Dynamic (Intelligence) | Binds ML models to entities and captures feedback for retraining | The organization's memory |
Together, these layers form a digital operational twin — a continuously updating model of enterprise reality.
4. Core Architecture Proposal
4.1 Layered Architecture Overview
| Layer | Core Components | Primary Function | Notes / Integration Details |
|---|---|---|---|
| 1. Ingestion & Integration | Airbyte, Kafka Connect, Debezium, Fivetran (optional) | Ingest batch and streaming data from databases, APIs, and files into the object store | Standard connectors populate raw and staging zones. Airbyte can directly write Parquet files or DuckDB tables. |
| 2. Storage / Lakehouse | Object Storage (S3 / MinIO) + Parquet + DuckDB-native files | Unified, columnar data store with transactional and analytical access | DuckDB directly queries Parquet/S3; no separate warehouse needed. This simplifies architecture and cost. |
| 3. Transformation & Semantic Modeling (DuckDB Core) | DuckDB + dbt-duckdb | Transform, join, and model datasets into semantic tables; materialize views for the Ontology graph | dbt-duckdb allows ELT pipelines directly in SQL with metadata tracking; transformations run locally or in containers. |
| 4. Semantic Ontology Layer (Business Objects) | Neo4j / ArangoDB + OpenMetadata | Represent real-world entities and their relationships using business semantics | DuckDB feeds curated tables into the graph; OpenMetadata tracks schema and lineage. |
| 5. Kinetic Layer (Operational Events) | Kafka / Redpanda + Flink / Faust | Capture and process live business events, linking them to ontology objects | Kafka topics store real-time "verbs" (actions) that enrich the semantic graph through microservices. |
| 6. Dynamic Intelligence Layer (ML & AI) | MLflow, Feast, Seldon Core | Bind ML models to entities; store features, predictions, and outcomes | DuckDB used for feature generation and lightweight training data assembly. |
| 7. Feedback & Orchestration | Dagster or Prefect, Kafka Consumers | Automate ETL, feature extraction, model retraining, and feedback ingestion | Orchestrates DuckDB transformations and model feedback loops. |
| 8. Visualization & UX | Apache Superset, Metabase, or React-based Explorer | Present dashboards, ontology browser, and decision capture UI | Superset can query DuckDB directly via SQLAlchemy; React UI calls APIs on the Ontology service. |
| 9. Governance & Observability | Keycloak, OPA, OpenMetadata, Prometheus + Grafana | Authentication, access control, lineage, and system monitoring | Metadata stored in OpenMetadata; observability pipelines integrate with DuckDB and Kafka metrics. |
4.1.1 Architectural Notes — DuckDB-Specific Adjustments
- Simplified Compute & Storage Footprint:
- DuckDB operates directly on Parquet/S3 data, removing the need for Spark clusters or separate warehouses.
- Ideal for small-to-mid workloads and early-stage startups aiming for minimal infrastructure overhead.
- Native Integration with dbt:
- dbt-duckdb allows defining semantic transformations as SQL models, directly building analytical tables for ontology ingestion.
- Supports incremental models, materialized views, and lineage tracking.
- Semantic Layer Bridge:
- Transformed tables in DuckDB represent the canonical "truth layer."
- An export service (Python microservice or dbt task) syncs object relationships to the Neo4j Ontology graph.
- Operational Efficiency:
- Analytical queries, joins, and aggregations execute in-memory via DuckDB with vectorized execution.
- Perfect for powering Superset dashboards or feature generation without latency typical of remote warehouses.
- Data Scale Considerations:
- Works best for datasets up to ~100–500 GB active footprint (per node).
- For larger scales, integrate MotherDuck or Trino over DuckDB later, maintaining the same data model.
- Feedback Integration:
- Decision feedback or ML outcomes are stored in DuckDB tables and periodically merged into the training set or semantic graph, maintaining local consistency.
- Deployment Simplicity:
- Single binary + S3 connectivity = minimal maintenance.
- Perfectly containerized for Kubernetes jobs or local testing pipeline.
4.1.2 Recommended Extensions (DuckDB Roadmap)
- MotherDuck Integration: scale compute elastically via cloud DuckDB.
- Materialized Ontology Views: store entity-relationship snapshots in DuckDB for analytics.
- Streaming Connectors: use DuckDB's incremental ingestion mode for Kafka topics.
- Direct Feature Engineering: compute ML features in DuckDB and publish to Feast offline store.
4.2 Data & Control Flow
- Data Sources → ETL (Airbyte/dbt) → Semantic Graph (Neo4j)
- Events → Kafka → Update Kinetic Layer (entity state changes)
- Models → MLflow + Seldon → Bind predictions to entities
- Operator or System Decisions → Feedback API → Kafka feedback topic
- Feedback → Dagster retrains models → Updated models redeployed
4.3 Ontology Integration within the Closed Loop
- Semantic Layer: Establishes a consistent business context for all data.
- Kinetic Layer: Streams continuous operational updates.
- Dynamic Layer: Applies AI-driven optimization and captures new learnings.
These layers collectively realize a self-reinforcing operational intelligence loop.
5. Technology Stack & Open-Source Alternatives
| Function | Recommended OSS | Alternatives | Notes |
|---|---|---|---|
| Ontology Graph Store | Neo4j | ArangoDB, RDF4J | Developer-friendly with Cypher querying |
| Metadata & Catalog | OpenMetadata | DataHub, Amundsen | Provides lineage and discoverability |
| Data Transformation | dbt-core | Spark, Trino | Lightweight SQL-based modeling |
| Event Streaming | Kafka + Flink | Pulsar | Reliable high-throughput event pipeline |
| Workflow Orchestration | Dagster | Airflow, Prefect | Data-aware scheduling and monitoring |
| Feature & Model Ops | MLflow + Feast + Seldon | KServe, BentoML | Full ML lifecycle management |
| Visualization | Superset / React | Metabase | Business-friendly visualization |
| Auth & Governance | Keycloak + OPA | Auth0 | Central identity and policy management |
| Infra & Observability | Kubernetes, Terraform, Prometheus, Grafana | — | Cloud-native deployment standard |
6. Data & Workflow Model
6.1 Semantic Modeling Example
(Customer)-[:PLACED]->(Order)
(Order)-[:CONTAINS]->(Product)
(Product)-[:SUPPLIED_BY]->(Vendor)
(Asset)-[:LOCATED_AT]->(Facility)Each node aggregates attributes from multiple source systems (CRM, ERP, IoT).
6.2 Kinetic Event Model
Event Example:
{
"event_id": "uuid",
"timestamp": "2025-11-12T09:32Z",
"type": "ORDER_SHIPPED",
"actor": "Order_789",
"target": "Customer_123",
"attributes": {"status": "delivered"},
"source": "logistics_api"
}This event updates the graph and triggers downstream logic, maintaining a real-time operational view.
6.3 Dynamic Intelligence Feedback Loop
- Models (e.g., churn prediction) are bound to entities via metadata.
- Predictions are published as events.
- Decision outcomes are captured and merged into labeled training datasets.
- Dagster orchestrates retraining workflows, completing the learning loop.
7. Functional Decomposition
| Layer | Feature / Component | Description |
|---|---|---|
| 1. User Interface | Dashboards & Decision Capture UI | Provides real-time views into KPIs, ontology objects, and feedback submission forms. Built using React (for interactive decision capture) and Apache Superset or Metabase for self-service analytics. |
| 2. API Gateway / Access Layer | GraphQL + REST APIs | Exposes access to ontology data, graph relationships, and live event states. APIs aggregate data from DuckDB (semantic views) and the Neo4j graph. |
| 3. Data Pipeline (Transformation) | dbt-duckdb + Airbyte / Kafka Connect | Handles ingestion, cleaning, normalization, and semantic model creation directly in DuckDB. dbt projects define semantic transformations and lineage. |
| 4. Graph Engine (Semantic Ontology Layer) | Neo4j / ArangoDB Service | Stores and manages relationships between business entities and events. Consumes materialized semantic tables from DuckDB to update graph nodes/edges. |
| 5. Event Bus (Kinetic Layer) | Kafka + Flink / Faust | Captures and processes real-time actions (e.g., order placements, maintenance events). Links events to ontology entities by updating both DuckDB and Neo4j. |
| 6. AI / ML Services (Dynamic Layer) | MLflow + Feast + Seldon Core | Manages model registry, feature storage, and online inference. Feature extraction and training data preparation occur in DuckDB. |
| 7. Feedback & Orchestration | Dagster / Prefect + Kafka Consumers | Orchestrates transformations, feedback ingestion, and model retraining. Executes dbt-duckdb jobs, runs ML pipelines, and tracks lineage. |
| 8. Governance & Observability | Keycloak + OPA + OpenMetadata + Prometheus / Grafana | Provides authentication, access policies, lineage visualization, and system metrics. DuckDB table metadata integrates with OpenMetadata. |
8. Implementation Roadmap
| Phase | Duration | Key Deliverables |
|---|---|---|
| 1. Semantic Core | 4–6 weeks | Graph schema, data ingestion, catalog deployment |
| 2. Kinetic Layer | 4 weeks | Event ingestion, streaming updates to ontology |
| 3. Dynamic Layer | 6 weeks | MLflow setup, model-to-entity binding |
| 4. Feedback & UX | 4 weeks | Decision capture UI and feedback pipeline |
| 5. Governance & Observability | 3 weeks | Role-based access, monitoring, and lineage tracking |
Estimated MVP timeline: ~4–5 months for a 4–5 member data/ML team.
9. Risks & Mitigations
| Risk | Description | Mitigation |
|---|---|---|
| Graph Performance | High event volume affects Neo4j scalability | Partition by domain; archive cold data in Delta Lake |
| Feedback Bias | Reinforcement of model errors | Human-in-loop validation and versioned retraining |
| Integration Complexity | Managing multiple OSS components | Use managed services (e.g., Neo4j Aura, Confluent Cloud) |
| Ontology Drift | Business model divergence | Regular domain reviews and schema version control |
| Security Gaps | Data exposure or misuse | Enforce OPA policies, encryption, and audit trails |
10. Competitive Insight
| Dimension | Palantir Foundry | MVP Equivalent |
|---|---|---|
| Architecture Depth | Fully integrated data-to-decision stack | Modular open-source composition |
| Ontology Engine | Proprietary, adaptive | Neo4j / GraphDB-based implementation |
| Operational Integration | Enterprise-wide real-time workflows | Kafka + Flink streaming integration |
| Feedback Intelligence | Embedded continuous learning | MLflow + Feast + retraining automation |
| User Experience | Polished low-code platform | Lightweight React dashboard |
| Cost & Flexibility | Enterprise-grade, high cost | Cloud-native, cost-efficient MVP |
11. Suggested Future Extensions (Version 2.0)
- Ontology Builder UI: Drag-and-drop schema and relationship editor
- Temporal Graphing: Time-based versioned entity states
- Simulation Layer: "What-if" scenario modeling
- Causal Inference Engine: Policy optimization through causal ML
- Domain Ontology Templates: Industry-specific accelerators
- AI Copilot: LLM-powered schema mapping and graph querying
- Edge & IoT Integration: Real-time feedback from devices and sensors
- Data Provenance & Trust Scoring: Traceable, auditable decision lineage